- K3s, Longhorn, Redis Sentinel, Qdrant, Neo4j, Prometheus, and Grafana form the operating base.
- Chat messages pass through sidecar routing, model selection, task detection, hybrid recall, context build, backend selection, and blocking persistence.
- Memory already spans Redis working state, Qdrant semantic vectors, Neo4j graph facts, LangGraph procedural state, and archive storage.
Reading mode
System Deep Dive
Evolution map: May 2026
Astra, a cognitive AI platform evolving into a graph-native nervous system.
Astra is a production-grade cognitive system running on K3s across four machines with 84 CPU cores, 845GiB of RAM, 120GB of NVIDIA VRAM, a 6-layer memory architecture, real-time audio and video perception, dream-cycle consolidation, LangGraph agent orchestration, and a full Prometheus and Grafana observability surface. The inference layer is model-agnostic: Gemma-family models are one strong current lane, but selected models, backend adapters, and router decisions can swap as better models arrive. The next architecture lane is graph-native: H2-GNN retrieval, temporal memory, structural surprise routing, vLLM-oriented inference, and Video-LLaMA-style perception.

Evolution
Current platform, active refactor, graph-native future.
The refactor is not presented as finished work. The page separates what exists now from the architecture direction already described in Astra's design docs.
- Inference is moving toward vLLM-style always-loaded serving while preserving the same model-agnostic retrieval, capsule, and context pipeline.
- Voice and video work is being reorganized around lower-latency perception, stronger switching logic, and Video-LLaMA-style visual context.
- Model selection can be user-selected or router-selected; Gemma-family 27B is a current lane, not the identity of the system.
- Neo4j becomes training structure, Qdrant stores semantic and learned graph embeddings, and Redis holds temporal node state.
- GraphSAGE, R-GCN, H2-GNN, and TGN layers turn typed relationships into retrieval and reasoning signals.
- Structural surprise becomes a router signal when a claim violates learned graph topology.
Why This Is Hard
Most cognitive systems collapse into wrappers with extra nouns.
Astra is interesting because the work is not just model choice. The hard parts are routing, memory hierarchy, multimodal timing, service orchestration, graph structure, GPU pressure, and knowing which parts are current versus still evolving.
- One big model receives a long prompt, a few tools, and a dashboard that mostly reports vibes.
- Memory retrieval returns semantically similar text without structural checks or temporal state.
- Audio, video, routing, and post-processing fight for GPU headroom with no scheduling story.
- Split the chat path into sidecar routing, task detection, hybrid recall, context build, backend selection, and persistence.
- Use Neo4j, Qdrant, Redis, and typed temporal facts as a substrate for H2-GNN and TGN evolution.
- Frame vLLM, Video-LLaMA, model-router, and voice/video switching changes as active refactor lanes instead of pretending they are finished.
- The evolution map, GNN flow, chat pipeline breakdown, and staged roadmap show the operating shape.
- 32+ swappable model roles, 50 relationship channels, 87K+ memory prep, and 120GB VRAM give scale signals.
- Model dropdowns, backend adapters, and router paths make the stack better as models improve.
- Structural surprise, dream updates, and temporal graph state make the future direction legible.
Operating Proof
The architecture has running surfaces behind it.
These node01 screenshots avoid personal chat content and show the system-level surfaces: graph exploration, cognitive state, GPU model residency, Dream, SPICE, consolidation, and online learning.
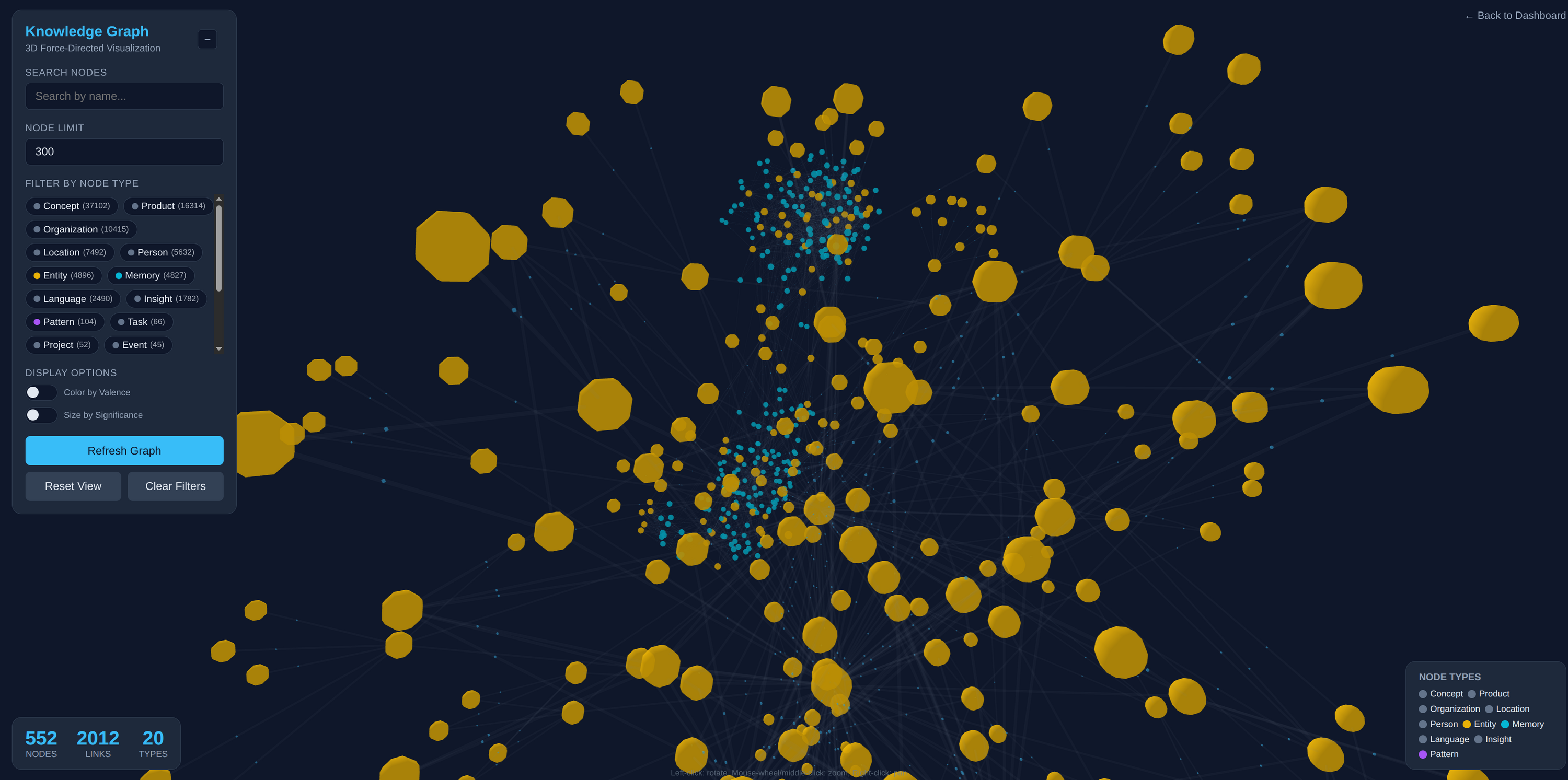
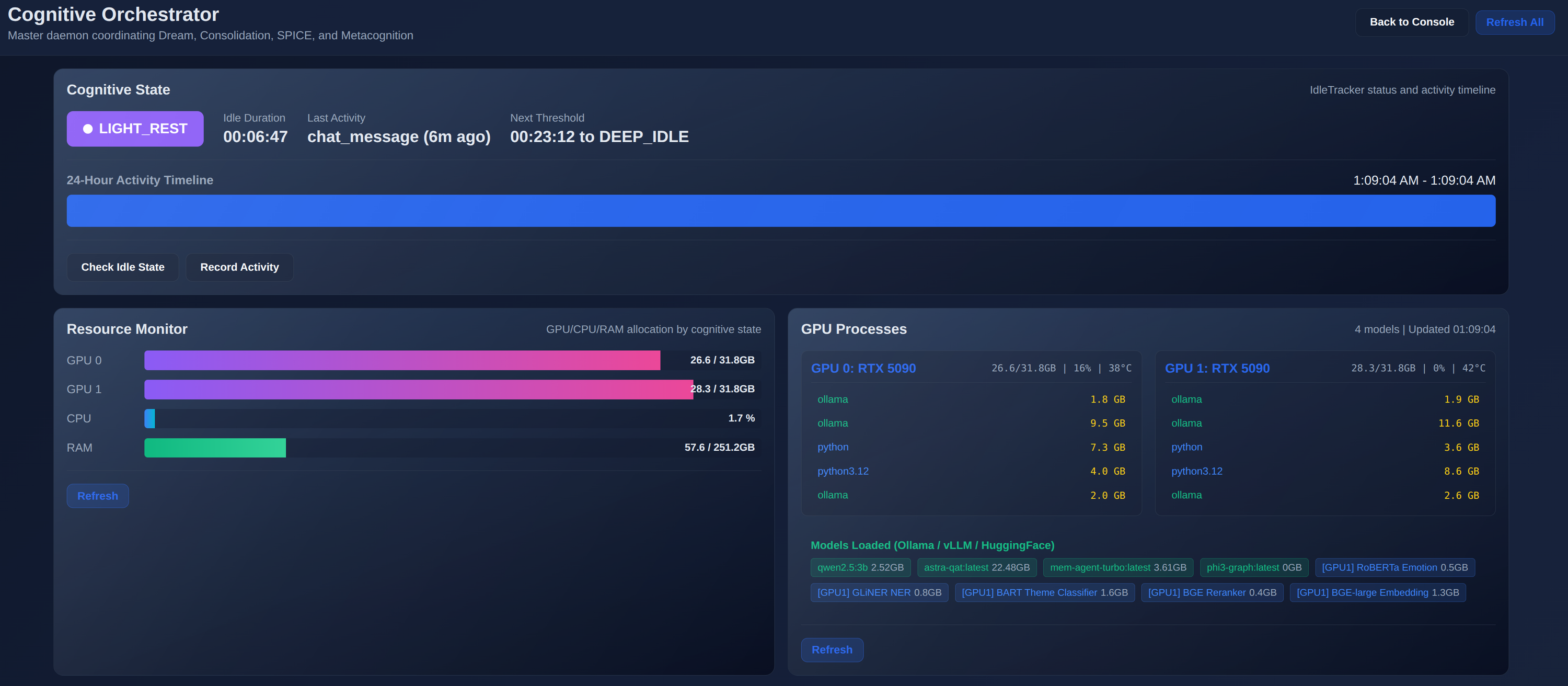
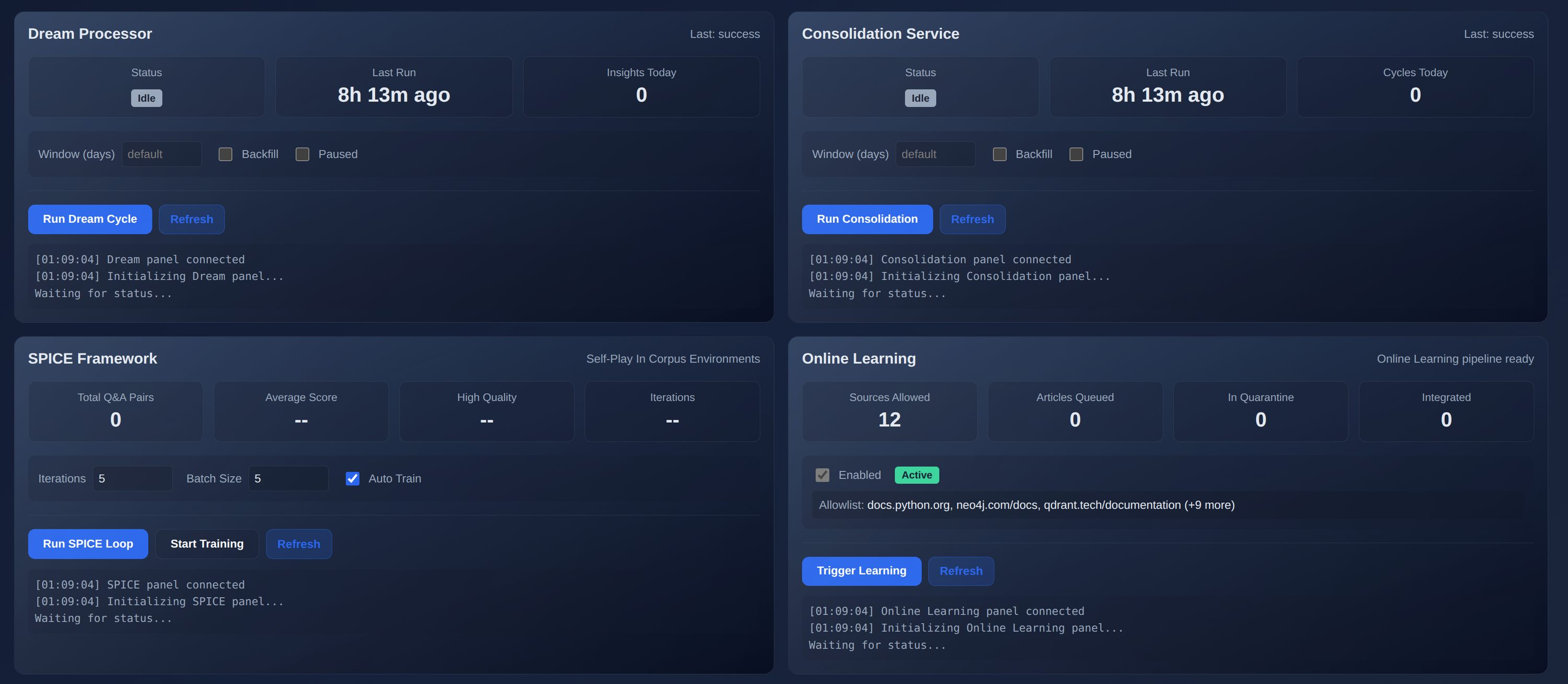
Hardware
Four machines, five GPUs, and a lot more than one box.
The current Astra hardware footprint spans node01, node02, node03, and node05. Together they provide 84 CPU cores, 845GiB of RAM, and 120GB of NVIDIA VRAM for orchestration, retrieval, inference, and support workloads.
- AMD Threadripper PRO 7975WX (32 cores / 64 threads)
- 503GiB RAM
- Dual NVIDIA GeForce RTX 5090 (32GB each)
- 3x Samsung 990 PRO 2TB NVMe
- AMD Ryzen 9 7950X3D (16 cores / 32 threads)
- 187GiB RAM
- NVIDIA GeForce RTX 3090 (24GB)
- Samsung 990 PRO with Heatsink 2TB NVMe
- AMD Ryzen 9 5900X (12 cores / 24 threads)
- 125GiB RAM
- NVIDIA GeForce RTX 5060 Ti (16GB)
- Samsung 990 PRO 2TB NVMe
- Intel Core Ultra 9 275HX (24 cores / 24 threads)
- 30GiB RAM
- NVIDIA GeForce RTX 5080 Laptop GPU (16GB)
- Samsung 990 PRO 2TB plus Samsung 1TB NVMe
Memory Architecture
Memory is becoming the training substrate.
Memory is not a feature bolted on. It is the infrastructure. Each layer has its own latency budget, retention policy, query interface, and now a clear path into graph learning.
- Redis Sentinel HA (master + 2 replicas + 3 sentinels)
- Sub-millisecond latency for session state and pub/sub
- Allkeys-LRU eviction with AOF + RDB persistence
- Qdrant vectors with HNSW index across 100k+ memory capsules
- Neo4j knowledge graph for long-term facts and Cypher queries
- BGE embeddings and reranking with CUDA acceleration
- Typed relationships, confidence scores, and temporal metadata prepare graph-learning inputs
- LangGraph checkpoints for learned skills and habits
- Neo4j relational reasoning and knowledge graph traversal
- Filesystem archive with daily backups and 7-day retention
- TGN node state planned as a cross-cutting Redis layer, not a replacement for existing memory
Chat Pipeline
Every response is routed through memory, tools, models, and persistence.

- Entry route creates a cycle ID, cognitive trace, idle activity record, and sidecar routing decision.
- Setup adds MCP tool augmentation, world-model checks, conversation resolution, and selected or router-chosen model routing.
- Hybrid recall pulls from Redis, Qdrant, and Neo4j before context construction and token budgeting.
- Backend selection happens after context build so vLLM and Ollama paths share the same memory pipeline.
- Persistence writes emotion, coherence, working memory, conversation turns, ingestion queue items, and capsule links.
- Core logic with v2.6 ModelRegistry (lazy-load singleton, 145–415ms responses)
- Dream processor for background memory consolidation cycles
- Emotional analyzer (RoBERTa sentiment and emotion)
- Fact extractor (GLiNER NER + Phi-3 graph extraction)
- SPICE loop for self-checking against documentation and memory ground truth
- Synaptic pruning for memory decay and archival
- Curiosity engine for gap detection and question generation
- Coherence checker for contradiction detection and resolution
- Cognitive orchestrator coordinating all reasoning daemons
Cognition and Routing
The model is a replaceable worker inside a larger cognitive loop.
Astra gets better when models get better because the memory pipeline, routing logic, tool layer, metacognition, coherence, and persistence are not locked to one base model.
- Backend adapters let Ollama and vLLM share the same recall, context, capsule, and persistence path.
- Workspace model selection already supports a model dropdown with persisted session choice.
- The active router lane can choose depth or base model through a smaller routing model when enabled.
- Metacognition estimates confidence and confabulation risk after generation.
- Coherence tracking watches contradiction and topic drift through embedding-based state.
- Curiosity checks knowledge gaps and can raise deeper retrieval or follow-up work.
- SPICE generates questions from docs, attempts answers, compares against ground truth, and flags repair work.
- Dream and consolidation cycles update memory state, prune stale material, and prepare graph supervision.
- Reflective routing can trigger deeper coherence and self-correction when confidence drops.
GNN Architecture
The knowledge graph stops being a lookup table.
The major architectural transfer is from explicit graph retrieval to learned graph structure: what should be connected, what looks anomalous, what is drifting, and what deserves consolidation.
Graph foundation
Fact extraction creates typed nodes, 50 relationship types, confidence scores, and backdated temporal metadata. That turns memory work into model-ready graph supervision.
Learned structure
GraphSAGE starts with scalable embeddings, R-GCN adds relation-aware message passing, H2-GNN becomes the primary heterogeneous model, and TGN adds temporal state.
Runtime signals
GNN embeddings enhance Qdrant retrieval, link prediction suggests implicit relationships, and structural surprise tells the router when a request should be verified more deeply.
Dream updates
Dream and consolidation cycles can fine-tune affected subgraphs, surface knowledge gaps, detect drift, and update graph embeddings without retraining the whole system every night.
Perception and Media
Real-time audio, video, TTS, and vision captioning.
- Capture service with Silero VAD and Whisper STT
- Kokoro-82M TTS with GPU-accelerated synthesis
- Audio processor for transcription and feature extraction
- FFmpeg video processor (webcam at 1280x720 @ 30fps MJPEG)
- Vision caption service (LLaVA INT8 image captioning)
- Janus WebRTC gateway with monitoring daemon
- CLIP embeddings for video frame analysis
- Video-LLaMA-style integration path for richer temporal visual context
Inference
Model-agnostic mesh today, vLLM-oriented serving tomorrow.
- GPU 0: current Ollama lanes (astra-qat/Gemma-family 27B, mem-agent, qwen2.5:3b)
- GPU 1: HuggingFace (BGE embed, BGE reranker, RoBERTa, GLiNER)
- Time-slicing: 4 replicas per GPU = 8 virtual GPU slices
- Dual sidecar architecture (qwen2.5:3b + mem-agent-turbo)
- User-selected and router-selected base model lanes with Gemma-family 27B as one current option
- vLLM path keeps memory retrieval, context build, and capsule access identical to Ollama
- Prometheus metrics with DCGM GPU exporter
- Grafana dashboards (LLM performance, fact extraction, TTS, pruning, metacognition)
- Pulse metrics API and health monitor with circuit breakers
Stack
The stack is becoming graph aware.
- K3s
- Longhorn
- Ollama
- vLLM
- Neo4j
- Qdrant
- Redis Sentinel
- Prometheus
- Grafana
- PyTorch Geometric path
- Model router
- LangGraph
- WhisperX
- Kokoro TTS
- LLaVA
- CLIP
- BGE
- GLiNER
- RoBERTa
- Janus WebRTC
- H2-GNN planning
- TGN memory path
- SPICE
- Coherence
- Curiosity
Roadmap
The graph transition has a staged path.
-
Phase 0
Data foundation
Relationship ontology, confidence scoring, temporal metadata, graph backfill, and calibration checks.
-
Phase 1
GraphSAGE baseline
Neo4j to PyG export, baseline embeddings, Qdrant storage, retrieval lift, and initial Grafana metrics.
-
Phase 2
Relation-aware H2-GNN
R-GCN basis decomposition across typed relationships, structural anomaly checks, and coherence integration.
-
Phase 3
Temporal graph layer
TGN memory in Redis, preference drift, trajectory forecasting, and temporal anomaly detection.
-
Phase 4
Dream integration
Maintenance-window graph updates, subgraph fine-tuning, knowledge-gap discovery, and consolidation feedback.
Need a cognitive system that actually runs on your own hardware?
That takes infrastructure design, not just a model API key.